groups
A scanlation group is a group of people who translate manga into their own language.
group summary
Click on a row to see the manga that the group has translated.
notes
building the model
We build a collaborative filtering model using the most straightforward possible relationship: making recommendations for a group based on other groups who have translated the same manga. We use the number of log-scaled pages translated as our “rating” that a group gives a manga. We build the model using the alternating least-squares (ALS) algorithm implemented in PySpark.
We choose group-manga recommendations as our first model because it is easy to find who has translated what. The collaborative filter is also how we would build a recommendation system for user-manga relationships. It serves as a proof of concept for building more complex models. Training the model and making predictions is relatively cheap computationally, taking less than two minutes to run on a 8-cores @ 3.4GHz . It takes far longer to copy the pre-computed predictions into static hosting due to the abundance of small files.
We also note some basic distributional properties of the data, that lead to over-recommendation of manhua series in the first iteration of the model that used unscaled page counts as ratings. As per @curche:
Most manhua are longstrip and when you upload longstrip, they get split into 10k pixels pages which means a LOT of pages. At the same time, manhua churn out too many chapters (like 3 per week for “Martial Peak”, which already has 10k+ chapters)
Here we plot histograms of chapter and page counts for all manga in the dataset.
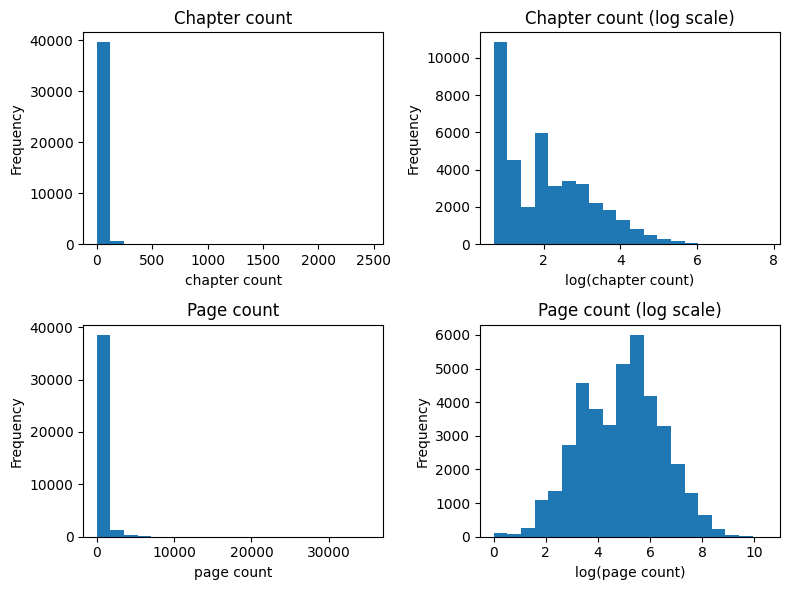
When we log-scale both axes, we see that the data takes on a more normal distribution. We also note an interesting bimodal distribution of chapter counts (i.e. there are two peaks). The second model uses log-scaled page counts as ratings, which should lead to saner recommendations.
The recommendations are bad. There are a few reasons for this:
- The data is sparse. There are many groups and manga, but a small overlap between the two.
- Scanlation groups tend to avoid sniping each other’s projects, so there is often only a single group translating a manga. Recommendations, therefore, tend to occur across groups that translate the same manga but in different languages.
Models we build in the future will be content-based, which means we will use similarities between descriptions and tags to make recommendations. The description-based recommendations will rely on title and description data embedded into vector space using techniques like word2vec or, more likely, GPT-2 via HuggingFace. For manga tags, we will build a bi-partite network between manga and tags. We project the manga-tag network into a unimodal manga network and then factorize the resulting adjacency matrix using an algorithm like ALS. We might compare the tag-based recommendations to alternative methods such as latent semantic indexing (LSI).
serving the model
We take inspiration for model service from similar-manga. This project builds a manga-manga recommendation model using LSI on tags. They pre-compute recommendations for all manga and serve them as static content from a GitHub repository.
We also host our model as static content in a Google Cloud Storage bucket and provide an API for the group recommendations at the following endpoint:
/api/v1/models/group-manga/recommendations/{group_id}.jsonThe API redirects to the static content in the bucket. Note that the API is subject to change at any time, but like all other content on this site, is made freely available to experiment with.
changelog
- 2022-12-18 - initial model using ALS on group-manga using page count as rating
- 2022-12-19 - use
log(page_count + 1)as rating so ratings are normally distributed